31 January 2013
Advanced DAX, Business Analytics, HDInsight
When you registered, you asked to be notified about new content—here's our newsletter, sent every month or two.
Summary of New Content:
- Microsoft Business Analytics Roadshow slides (4 PPT decks, registered members)
- Querying with DAX (46 min video, Full Access Members)
Querying with DAX
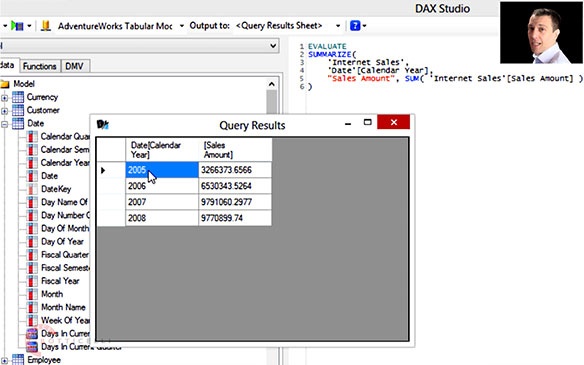
Did you know that Data Analysis Expressions (DAX) is useful for querying data, in addition to its more common use for defining measures and calculated columns in PowerPivot or tabular models? Marco Russo, from sqlbi.com, explains the tools, including the free DAX Studio, and the syntax necessary for writing DAX queries in Querying with DAX, our newest, 46-minute video, containing 7 detailed demos, part of our series on DAX. You will learn about the EVALUATE and CALCULATETABLE statement, how to control projection of data by using ADDCOLUMNS and SUMMARIZE functions, how to use the ROW function to test new measures for your data model, and how to use DAX measures within MDX queries. Marco even covers the impact of one-level and two-level caching mechanisms on your query performance. By learning these concepts you will be able to use DAX queries as a data source for your reports, and for Excel tables.
News
I am on the road with our 2013 roadshow, called Microsoft Business Analytics. What is Microsoft Business Analytics? It is a combination of BI, Big Data, and Data Warehousing. It is an umbrella term created to bring together those three technologies. In my seminars I cover what is new, including: SharePoint 2013, brand-new Office 2013, SQL Server 2012 SP1, HDInsight, analytics in the private and public clouds, and advanced analytics including geospatial. You can download the 4 PPT decks from here. Consider joining me, if you are in one of the countries, which I am visiting—see the schedule. My key theme is that in order to make analytics more powerful, we have to make it simpler for the user, hence: Power and simplicity. This applies to traditional analytics, but even more so to big data. I will record portions of the show and we will offer them as videos later this spring for the many of you who cannot join me on the road.
I am also speaking at the European SharePoint Conference, next week in Copenhagen, where I will keynote with my "Attractive Business Intelligence" tour-de-force of the entire Microsoft BI stack, in its newest release. I'll post the PPT on our web site, next week.
Microsoft HDInsight vs Data Mining for Big Data
I am amazed by the power of big data technologies, such as Microsoft HDInsight, based on Apache Hadoop, which I show in extensive demos, during the current roadshow. I am reserved, however, about the immediate wide-scale usefulness of the technology—it is still slightly geeky, which makes it wonderful for those who have the skills and can write MapReduce jobs, Pig Latin programs, or can use Mahout for machine learning. Indeed, during the show, I demonstrate how a simple recommendation engine can be built using the Mahout library, with no coding, and by using HDInsight for Windows Azure. It works well, and it returns a useful, if perhaps not exciting-looking, numerical result. Interestingly, a similar recommendation engine can be built using a much older, and a more mature technology of data mining, part of every SQL Server since 2005. So which one is the right way to go? If you have the choice, I think choosing the simpler, more tested, visually richer and much easier to use SQL Server 2012 data mining is the one to go for. Why would I then suggest learning about Mahout and running it using HDInsight? Because it can scale to much larger data sets, ones that SQL Server data mining would not usually scale to.
Nevertheless, it would be a mistake to suggest that if you have a large data set, you automatically need the impressive scalability of an otherwise batch-oriented, large-latency Hadoop solution. In fact, through a reasonable sampling of the large data set we can easily reduce it to a smaller one, and once it goes through the SQL Server data mining engine it will produce almost identical recommendations to those obtained using Hadoop. Of course, if sampling is not an option, for example for a highly unstructured set, or the data set is just very large or fast, and you want to analyse it all, Hadoop will be the only way, for now (and Apache Drill in a few years). Besides, what is a really large data set? What size can we process using just the old-fashioned data mining in SQL? You would be surprised. Dealing with tens of millions and more rows is OK for SQL. However, if your data set is in GBs/TBs you might be more successful scaling it using Hadoop, unless something like a PDW is an option for you. There are no easy answers here, it depends on the complexity of your data set and the complexity of your query.
Please don't think I am trying to discourage you from Hadoop—on the contrary, learn it and try it, please! Do not, however, think that it will replace traditional approaches, such as those based on a good and a fast relational data warehouse. The value of a Hadoop solution lies specifically with those non-traditional data sets that we couldn't process using a relational approach. And if you are a company who has those, and has a good business reason to analyse them—bingo: Hadoop is your answer! But do me a favour, please, and read this interesting article by Microsoft Research suggesting that large memory (#BigMemory) might be even more important than high-level parallelism for typical big data sets of 9–15GB: "Nobody ever got fired for using Hadoop on a cluster".
Watch out for our future articles and videos, as we will be covering all the new technologies in the Microsoft BI stack, with a focus on analytics, including, of course, HDInsight and Hadoop.
The next most immediate videos will be recorded by Chris Webb, who will be expanding our MDX learning section in February and March. He is also teaching excellent, live courses focused on analytics later this year. Please find his full schedule here.
January Newsletter Promotion—10% Off!
For our faithful readers who get to this point in the newsletter there is a 10% discount valid on all memberships, including the group ones, until the end of February. Use code NEWSLETTER2013JAN at checkout (don't forget to click "Apply to order"). You can use it to buy a new membership, or to extend your existing one.
Thanks for reading and I hope you enjoy your membership,
Rafal Lukawiecki, Strategic Consultant and Director, Project Botticelli Ltd